I am continuing my blog series on HTTP Request Smuggling or HTTP Desync attacks. These vulnerabilities arise when there is a mismatch in handling between the frontend and backend servers. Understanding where a request ends and where the next request starts might not be the same between the different layers of a web application, and this can be especially true for modern apps that take advantage of microservices architectures. It can be very difficult to ensure all of the disparate pieces of an application handle requests consistently and are not vulnerable to a desync.
Again, the goal of this post is to not only help you solve the associated lab on the PortSwigger Web Security Academy site, but to understand the vulnerability, how to construct the payloads, and how to reproduce when testing against different web applications.
In my previous blog post (here), I explored the CL.TE vulnerability and solved the associated lab on the Web Security Academy. With the CL.TE vulnerability in the previous post, the frontend was not conforming to spec as it was honoring Content-Length over Transfer-Encoding. Given the difference in how the frontend and backend were determining the length of a request, it was possible to cause a desync and leave a partial request (in that case the letter ‘G’) in queue on the backend.
With the TE.CL vulnerability, the opposite behavior is in play: the frontend is conforming to spec by accepting and honoring the Transfer-Encoding header, while the backend honors the Content-Length header and ignores the Transfer-Encoding header. Again, there is a mismatch which opens the door for request smuggling.
Headers for which to watch:
Per the HTTP Specification, both headers are allowed to be in the same request, however, Transfer-Encoding should always take precedence if both headers are present.
Again, I will be focusing on the labs from the Portswigger Web Security Academy.
![]()
Take this request:
POST / HTTP/1.1
Host: victimsite.com
Transfer-Encoding: chunked
Content-Length: 3E
userid=scomurr
0
All systems handling the request should honor Transfer-Encoding: chunked. If a system honors the Content-Length: 3, that system will only see ‘E\r\n’ (remember the standard characters for terminating a line in an HTTP request count towards content length).
NOTE: With a TE payload, remember that the first value in the overall payload is the length of the content intended for this request in hexadecimal. That content is terminated by a ‘\r\n’ to get a a new line, a ‘0\r\n’ to get to a new line, and one more ‘\r\n’ for good measure. Watch Inspector within Burp to see the end of line characters as well as harvesting the hexadecimal values for the length of the content.
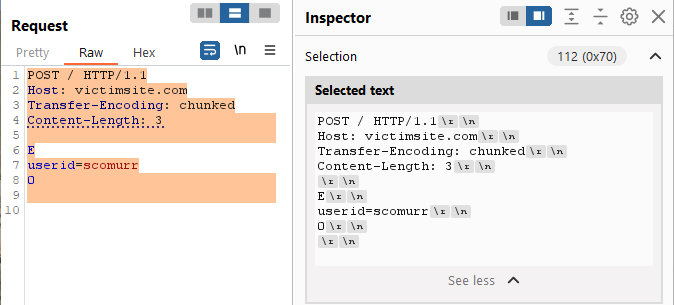
Conceptually, this vulnerability is very similar (despite being opposite) to the vulnerability from the previous post, so on to the lab –> Lab: HTTP request smuggling, basic TE.CL vulnerability
The goal with this lab is to cause a GPOST request to be triggered, once again resulting in a response error since GPOST is not a valid HTTP verb. In the previous blog post, it was enough to queue a ‘G’ on the backend so that ‘G’ would be prepended to any request when processed by the backend. Since the backend honors Content-Length in this case, the attack needs to be crafted a bit differently. Let’s dig into the specifics as to why.
Step 1: Open the Burp built in browser. Again, this is amazing as we no longer have to fiddle with getting Burp to proxy the traffic from an external browser.

Step 2: Browse to the lab URL and the traffic will start flowing into the proxy logs. Grab the GET request to / and send that to repeater.

Step 3: We need to be able to send a request body if the page has the potential to be vulnerable. In Repeater, change the request from a GET to a POST and resend.
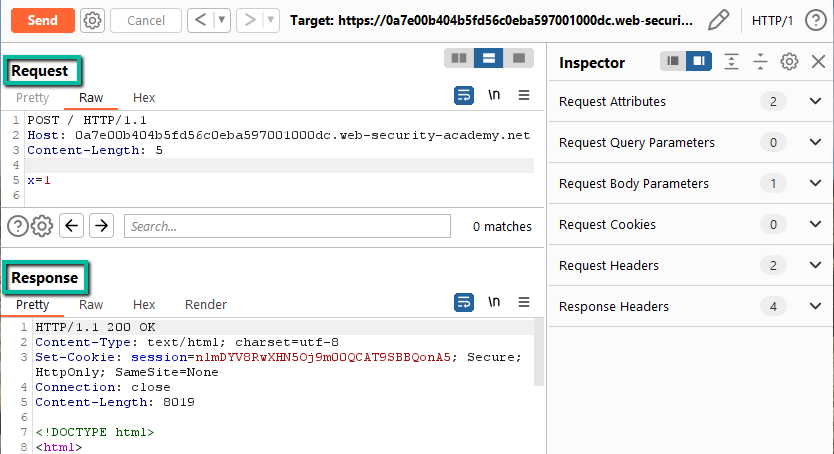
In this case, changing the GET to a POST gives us back a 200 so we can work with this page. I additionally added in a POST body of ‘x=1’ just to ensure passing content would not cause an issue. I also removed all of the extra headers from the request that are not needed as part of this lab.
Step 4: Next is to test to see if we can use both Content-Length and Transfer-Encoding headers within the same request. There are implementations that will reject the request if both headers are present.

Notice I did not prevent Burp from updating the Content-Length. If we are to assume that the frontend is honoring Transfer-Encoding, then the payload it would process would be the 3 characters after the ‘3’ (x=1) while the backend is going to honor Content-Length and process all of the highlighted content – the ‘3’ through the ‘0\r\n\r\n’.
Now that we see both headers can be included with appropriate lengths assigned to both CL and TE, on to the next step.
Step 5: Here’s where the attack really deviates from the CL.TE approach. With the CL.TE, adding a trailing ‘G’ to the payload works as long as the frontend knows to include the character in the request. In that case, all you have to do is increment the Content-Length by 1 and the trailing ‘G’ is included. In this case, we have Transfer-Encoding being honored by the frontend so our intended payload needs to be within the TE payload.
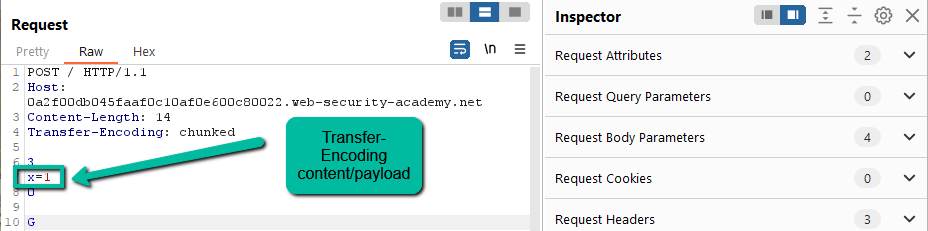
This makes the attack slightly more complex. Since the request above has the trailing ‘G’, it actually causes a 500 error on the frontend. We need to work around this. The next step is to disable Repeater –> Update Content-Length:
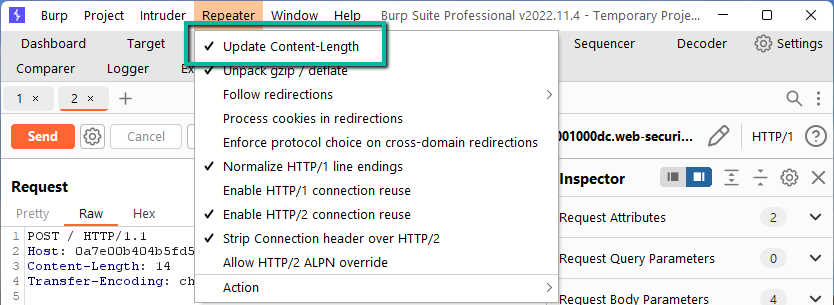
Unchecking this allows us to manipulate the Content-Length header.
Step 6: Now we have to focus on getting the correct payload into the TE content and then use the Content-Length header to chop the payload in the right spot such that characters are prepended to the request. This won’t actually work quite as intended or sufficiently such that it solves the lab, but we want to show what happens as this leads to how we have to proceed.

This looks good. The frontend will process the full request payload. The backend will process the request through the ‘1\r\n’. This means that the next character sitting in queue on the backend will be a ‘G’. Now to send the second request:
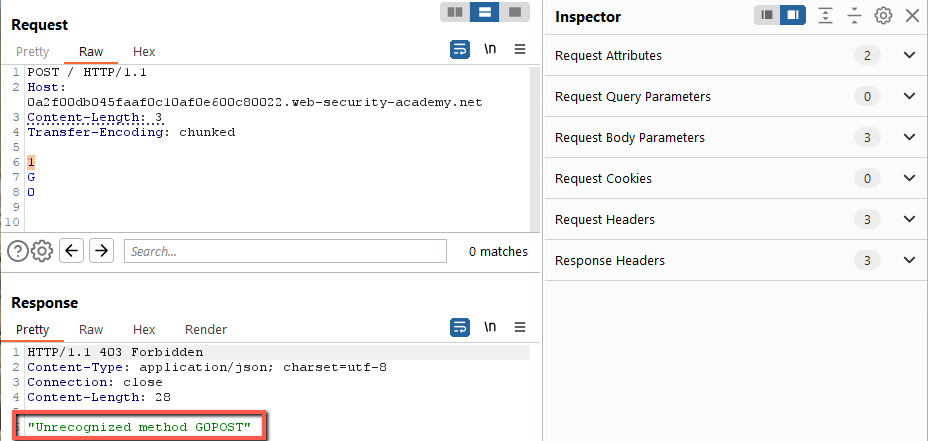
No good! We’re looking for GPOST – not G0POST.
Step 7: With the TE.CL vulnerability like this, the route forward is to include the entire intended request. We’re looking for an invalid HTTP verb of GPOST, so the next step would be to update the request such that a full second request is embedded and ready to be queued by the backend. Let’s break the request down since it’s a bit complex. The full request (handled by the frontend) is two backend payloads (with the top level Content-Length cutting the request in half). Here’s the request from the perspective of the frontend:

This ensures the full request payload passes the frontend. The highlighted payload is 110 characters long (6e in hexadecimal). All of this content is formatted correct, conforms to a Transfer-Encoded: chunked payload, and will be passed to the backend.
Here’s the first backend payload:

Since we want the backend to handle the request all the way up to GPOST, we specify a length that cuts the payload right before the start of the second payload. Note: a CL of either 3 or 4 works in this case since the \n doesn’t constitute a full new line and is ignored in this lab. I think a Content-Length of 4 is cleaner and will potentially avoid issues depending on the backend implementation.
Here’s the second backend payload:

This is the content that will get queued in the backend and released upon receipt of the next request. Notice that it is a full request with a payload. It has the HTTP verb, the path, the protocol, the host, and the Content-Length header with an actual payload. This is a fully formed request the backend is willing to accept.
There is, however, an interesting element here. The lab can be solved with a Content-Length: 12 header specified within this second embedded payload, however, you will always receive a 200 and a normal response on the client side. This is because the backend will catch the request with a CL: 12 header and process it immediately since it is a fully formed request. No queueing happens. In order to trigger queueing, we need to make the backend wait for at least one more character before releasing the GPOST request. By specifying a Content-Length longer than the provided payload (within the second embedded request), the backend server waits for more data before processing and releasing.
With a Content-Length of 13, this looks good!
Step 8: Send the request twice – done!
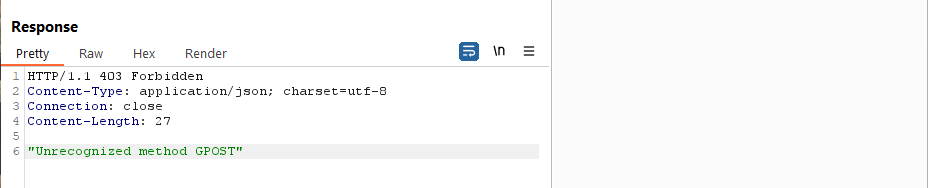
This attack really highlights the potential for HTTP Request Smuggling. In this lab we sent through an entire request, had it queued in the backend by setting the Content-Length 1 extra character long, and request was released on a second request. Imagine constructing a legitimate request (not a GPOST but a valid HTTP verb) and queueing it in the backend. Depending on implementation, the backend may rely on a different component of the application to ensure authentication and authorization. If that is the case, a request could be queued by an attacker and released by a completely different user. This could be used to exfiltrate credentials, data, or cause harm by executing an administrative activity.
Key notes for TE.CL vulnerabilities and this lab:
- Since this attack requires requests to be embedded inside of a larger request, pay special attention to Inspector and watch to make sure you have the appropriate \r\n to terminate intended lines.
- Make sure the Content-Length header within the second embedded request is at least 1 character extra in length to ensure the request gets queued on the backend. Otherwise, the lab will solve but you will not see GPOST sent back to client side.
Happy hunting!